
MIT 6.824 2022 notes 2 chinese version
Lecture 2:RPC and threads
为什么用 Go
- 语法先进。在语言层面支持线程(goroutine)和管道(channel)。对线程间的加锁、同步支持良好。
- 类型安全(type safe)。内存访问安全(memory safe),很难写出像 C++ 一样内存越界访问等 bug。
- 支持垃圾回收(GC)。不需要用户手动管理内存(特别是shared memory),这一点在多线程编程中尤为重要,因为在多线程中你很容易引用某块内存,然后忘记了在哪引用过。
- 简洁直观。没 C++ 那么多复杂的语言特性,并且在报错上很友好。
线程(Threads)
线程为什么这么重要?因为他是我们控制并发的主要手段,而并发是构成分布式系统的基础。在 Go 中,你可以将 goroutine 认为是线程,以下这两者混用。 每个线程可以有自己的内存栈、寄存器,但是他们可以共享一个地址空间。
使用原因
IO concurrency(IO 并发):一个历史说法,以前单核时,IO 是主要瓶颈,为了充分利用 CPU,一个线程在进行 IO 时,可以让出 CPU,让另一个线程进行计算、读取或发送网络消息等。在这里可以理解为:你可以通过多个线程并行的发送多个网络请求(比如 RPC、HTTP 等),然后分别等待其回复。
Parallelism(并行):充分利用多核 CPU。
关于并发(concurrency)和并行(parallelism)的区别和联系,可以看这篇文章。记住两个关键词即可:逻辑并发设计 vs 物理并行执行。
Convenience(方便):比如可以在后台启动一个线程,定时执行某件事、周期性的检测什么东西(比如心跳)。
Q&A:
- 不使用线程还能如何处理并发?基于事件驱动的异步编程。但是多线程模型更容易理解一些,毕竟每个线程内执行顺序和你的代码顺序是大体一致的。
- 进程和线程的区别?进程是操作系统提供的一种包含有独立地址空间的一种抽象,一个 Go 程序启动时作为一个进程,可以启动很多线程,共享地址空间(不过我记得 Goroutine 是用户态的执行流)。
使用难点(challenges)
共享内存易出错。一个经典的问题是,多个线程并行执行语句:n = n + 1 时,由于该操作不是原子操作,在不加锁时,很容易出现 n 为非期望值。
我们称这种情况为竞态 (race):即两个以上的线程同时试图改变某个共享变量。
解决的方法是加锁,但如何科学的加锁以兼顾性能并避免死锁又是一门学问。
Q&A:
- Go 是否知道锁和资源(一些共享的变量)间的映射?Go 并不知道,它仅仅就是等待锁、获取锁、释放锁。需要程序员在脑中、逻辑上来自己维护。
- Go 会锁上一个 Object 的所有变量还是部分?和上个问题一样,Go 不知道任何锁与变量之间的关系。Lock 本身的源语很简单,goroutine0 调用 mu.Lock 时,没有其他 goroutine 持有锁,则 goroutine0 获取锁;如果其他 goroutine 持有锁,则一直等待直到其释放锁;当然,在某些语言,如 Java 里,会将对象或者实例等与锁绑定,以指明锁的作用域。
- Lock 应该是某个对象的私有变量?如果可以的话,最好这样做。但如果有跨对象的加锁需求,就需要拿出来了,但要注意避免死锁。
线程协调(Coordination)
channels:go 中比较推荐的方式,分阻塞和带缓冲。
信道可用于在其他协程结束执行之前,阻塞 Go 主协程。
sending data from one thread to another and breeding that they did to be sent
sync.Cond:信号机制。
condition variables: 当前线程占用了锁,告诉其他等 待的线程继续等待,因为自己的确正在使用
waitGroup:阻塞知道一组 goroutine 执行完毕,后面还会提到。
死锁(DeadLock)
产生条件:多个锁,循环依赖,占有并等待。
if your program is just doing nothing but not crashed, the you have to check if there is a deadlock.
GO协程
GO协程是什么
Go 协程是与其他函数或方法一起并发运行的函数或方法。Go 协程可以看作是轻量级线程。与线程相比,创建一个 Go 协程的成本很小。因此在 Go 应用中,常常会看到有数以千计的 Go 协程并发地运行
协程相比于线程的优势
- 相比线程而言,Go 协程的成本极低。堆栈大小只有若干 kb,并且可以根据应用的需求进行增减。而线程必须指定堆栈的大小,其堆栈是固定不变的。
- Go 协程会复用(Multiplex)数量更少的 OS 线程。即使程序有数以千计的 Go 协程,也可能只有一个线程。如果该线程中的某一 Go 协程发生了阻塞(比如说等待用户输入),那么系统会再创建一个 OS 线程,并把其余 Go 协程都移动到这个新的 OS 线程。所有这一切都在运行时进行,作为程序员,我们没有直接面临这些复杂的细节,而是有一个简洁的 API 来处理并发。
- Go 协程使用信道(Channel)来进行通信。信道用于防止多个协程访问共享内存时发生竞态条件(Race Condition)。信道可以看作是 Go 协程之间通信的管道。
协程使用
调用函数或者方法时,在前面加上关键字 go,可以让一个新的 Go 协程并发地运行。
- 启动一个新的协程时,协程的调用会立即返回。与函数不同,程序控制不会去等待 Go 协程执行完毕。在调用 Go 协程之后,程序控制会立即返回到代码的下一行,忽略该协程的任何返回值。
- 如果希望运行其他 Go 协程,Go 主协程必须继续运行着。如果 Go 主协程终止,则程序终止,于是其他 Go 协程也不会继续运行。
例如:
package main
import (
"fmt"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
fmt.Println("main function")
}在第 11 行调用了 go hello() 之后,程序控制没有等待 hello 协程结束,立即返回到了代码下一行,打印 main function。接着由于没有其他可执行的代码,Go 主协程终止,于是 hello 协程就没有机会运行了。
改成
package main
import (
"fmt"
"time"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
time.Sleep(1 * time.Second)
fmt.Println("main function")
}在 Go 主协程中使用休眠,以便等待其他协程执行完毕。第 13 行,我们调用了 time 包里的函数 Sleep,该函数会休眠执行它的 Go 协程。在这里,我们使 Go 主协程休眠了 1 秒。因此在主协程终止之前,调用 go hello() 就有足够的时间来执行了。该程序首先打印 Hello world goroutine,等待 1 秒钟之后,接着打印 main function。
启动多个 Go 协程
package main
import (
"fmt"
"time"
)
func numbers() {
for i := 1; i <= 5; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Printf("%d ", i)
}
}
func alphabets() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("%c ", i)
}
}
func main() {
go numbers()
go alphabets()
time.Sleep(3000 * time.Millisecond)
fmt.Println("main terminated")
}在上面程序中的第 21 行和第 22 行,启动了两个 Go 协程。现在,这两个协程并发地运行。numbers 协程首先休眠 250 微秒,接着打印 1,然后再次休眠,打印 2,依此类推,一直到打印 5 结束。alphabete 协程同样打印从 a 到 e 的字母,并且每次有 400 微秒的休眠时间。 Go 主协程启动了 numbers 和 alphabete 两个 Go 协程,休眠了 3000 微秒后终止程序。
输出为
1 a 2 3 b 4 c 5 d e main terminate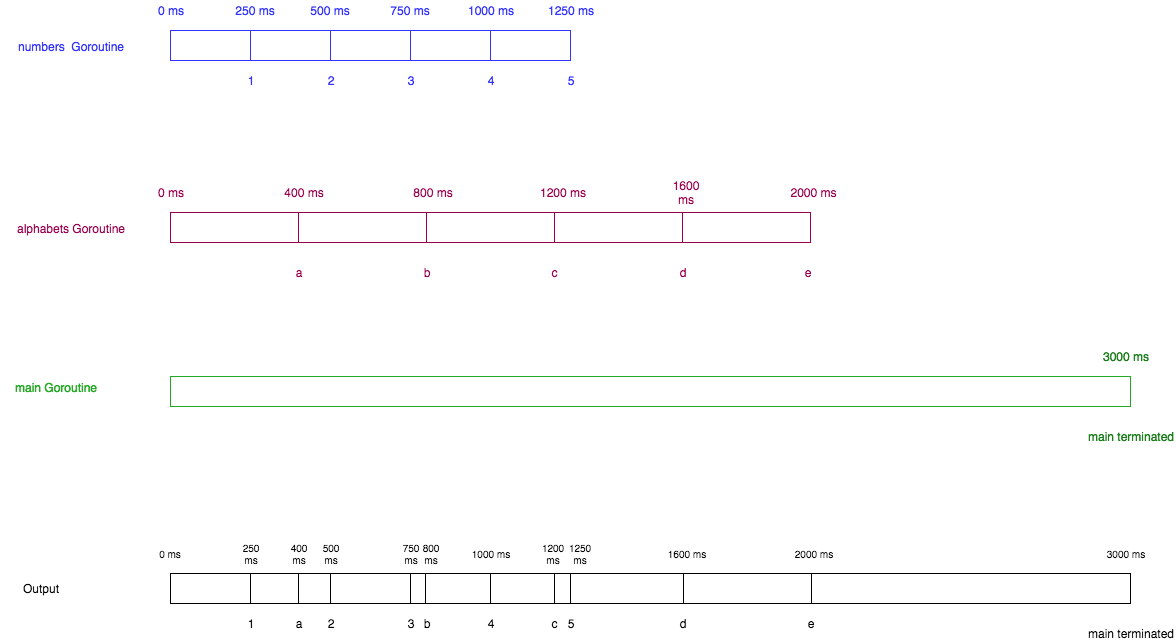
第一张蓝色的图表示 numbers 协程,第二张褐红色的图表示 alphabets 协程,第三张绿色的图表示 Go 主协程,而最后一张黑色的图把以上三种协程合并了,表明程序是如何运行的。在每个方框顶部,诸如 0 ms 和 250 ms 这样的字符串表示时间(以微秒为单位)。在每个方框的底部,1、2、3 等表示输出。蓝色方框表示:250 ms 打印出 1,500 ms 打印出 2,依此类推。最后黑色方框的底部的值会是 1 a 2 3 b 4 c 5 d e main terminated,这同样也是整个程序的输出。
信道
什么是信道?
信道可以想像成 Go 协程之间通信的管道。如同管道中的水会从一端流到另一端,通过使用信道,数据也可以从一端发送,在另一端接收。
信道的声明
所有信道都关联了一个类型。信道只能运输这种类型的数据,而运输其他类型的数据都是非法的。
chan T 表示 T 类型的信道。
信道的零值为 nil。信道的零值没有什么用,应该像对 map 和切片所做的那样,用 make 来定义信道。
下面编写代码,声明一个信道。
package main
import "fmt"
func main() {
var a chan int
if a == nil {
fmt.Println("channel a is nil, going to define it")
a = make(chan int)
fmt.Printf("Type of a is %T", a)
}
}由于信道的零值为 nil,在第 6 行,信道 a 的值就是 nil。于是,程序执行了 if 语句内的语句,定义了信道 a。程序中 a 是一个 int 类型的信道。该程序会输出:
channel a is nil, going to define it
Type of a is chan int简短声明通常也是一种定义信道的简洁有效的方法。
a := make(chan int)这一行代码同样定义了一个 int 类型的信道 a。
通过信道进行发送和接收
如下所示,该语法通过信道发送和接收数据。
data := <- a // 读取信道 a
a <- data // 写入信道 a信道旁的箭头方向指定了是发送数据还是接收数据。
在第一行,箭头对于 a 来说是向外指的,因此我们读取了信道 a 的值,并把该值存储到变量 data。
在第二行,箭头指向了 a,因此我们在把数据写入信道 a。
发送与接收默认是阻塞的
发送与接收默认是阻塞的。这是什么意思?当把数据发送到信道时,程序控制会在发送数据的语句处发生阻塞,直到有其它 Go 协程从信道读取到数据,才会解除阻塞。与此类似,当读取信道的数据时,如果没有其它的协程把数据写入到这个信道,那么读取过程就会一直阻塞着。
信道的这种特性能够帮助 Go 协程之间进行高效的通信,不需要用到其他编程语言常见的显式锁或条件变量。
信道的代码示例
理论已经够了:)。接下来写点代码,看看协程之间通过信道是怎么通信的。
首先引用前面教程里的程序。
package main
import (
"fmt"
"time"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
time.Sleep(1 * time.Second)
fmt.Println("main function")
}这是上一篇的代码。我们使用到了休眠,使 Go 主协程等待 hello 协程结束。
我们接下来使用信道来重写上面代码。
package main
import (
"fmt"
)
func hello(done chan bool) {
fmt.Println("Hello world goroutine")
done <- true
}
func main() {
done := make(chan bool)
go hello(done)
<-done
fmt.Println("main function")
}在上述程序里,我们在第 12 行创建了一个 bool 类型的信道 done,并把 done 作为参数传递给了 hello 协程。在第 14 行,我们通过信道 done 接收数据。这一行代码发生了阻塞,除非有协程向 done 写入数据,否则程序不会跳到下一行代码。于是,这就不需要用以前的 time.Sleep 来阻止 Go 主协程退出了。
<-done 这行代码通过信道使用done 接收数据,但并没有使用数据或者把数据存储到变量中。这完全是合法的。
现在我们的 Go 主协程发生了阻塞,等待信道 done 发送的数据。该信道作为参数传递给了协程 hello,hello 打印出 Hello world goroutine,接下来向 done 写入数据。当完成写入时,Go 主协程会通过信道 done 接收数据,于是它解除阻塞状态,打印出文本 main function。
该程序输出如下:
Hello world goroutine
main function我们稍微修改一下程序,在 hello 协程里加入休眠函数,以便更好地理解阻塞的概念。
package main
import (
"fmt"
"time"
)
func hello(done chan bool) {
fmt.Println("hello go routine is going to sleep")
time.Sleep(4 * time.Second)
fmt.Println("hello go routine awake and going to write to done")
done <- true
}
func main() {
done := make(chan bool)
fmt.Println("Main going to call hello go goroutine")
go hello(done)
<-done
fmt.Println("Main received data")
}在上面程序里,我们向 hello 函数里添加了 4 秒的休眠(第 10 行)。
程序首先会打印 Main going to call hello go goroutine。接着会开启 hello 协程,打印 hello go routine is going to sleep。打印完之后,hello 协程会休眠 4 秒钟,而在这期间,主协程会在 <-done 这一行发生阻塞,等待来自信道 done 的数据。4 秒钟之后,打印 hello go routine awake and going to write to done,接着再打印 Main received data。
信道的另一个示例
我们再编写一个程序来更好地理解信道。该程序会计算一个数中每一位的平方和与立方和,然后把平方和与立方和相加并打印出来。
例如,如果输出是 123,该程序会如下计算输出:
squares = (1 * 1) + (2 * 2) + (3 * 3)
cubes = (1 * 1 * 1) + (2 * 2 * 2) + (3 * 3 * 3)
output = squares + cubes = 50我们会这样去构建程序:在一个单独的 Go 协程计算平方和,而在另一个协程计算立方和,最后在 Go 主协程把平方和与立方和相加。
package main
import (
"fmt"
)
func calcSquares(number int, squareop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit
number /= 10
}
squareop <- sum
}
func calcCubes(number int, cubeop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit * digit
number /= 10
}
cubeop <- sum
}
func main() {
number := 589
sqrch := make(chan int)
cubech := make(chan int)
go calcSquares(number, sqrch)
go calcCubes(number, cubech)
squares, cubes := <-sqrch, <-cubech
fmt.Println("Final output", squares + cubes)
}在第 7 行,函数 calcSquares 计算一个数每位的平方和,并把结果发送给信道 squareop。与此类似,在第 17 行函数 calcCubes 计算一个数每位的立方和,并把结果发送给信道 cubop。
这两个函数分别在单独的协程里运行(第 31 行和第 32 行),每个函数都有传递信道的参数,以便写入数据。Go 主协程会在第 33 行等待两个信道传来的数据。一旦从两个信道接收完数据,数据就会存储在变量 squares 和 cubes 里,然后计算并打印出最后结果。该程序会输出:
Final output 1536死锁
使用信道需要考虑的一个重点是死锁。当 Go 协程给一个信道发送数据时,照理说会有其他 Go 协程来接收数据。如果没有的话,程序就会在运行时触发 panic,形成死锁。
同理,当有 Go 协程等着从一个信道接收数据时,我们期望其他的 Go 协程会向该信道写入数据,要不然程序就会触发 panic。
package main
func main() {
ch := make(chan int)
ch <- 5
}在上述程序中,我们创建了一个信道 ch,接着在下一行 ch <- 5,我们把 5 发送到这个信道。对于本程序,没有其他的协程从 ch 接收数据。于是程序触发 panic,出现如下运行时错误。
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
/tmp/sandbox249677995/main.go:6 +0x80单向信道
我们目前讨论的信道都是双向信道,即通过信道既能发送数据,又能接收数据。其实也可以创建单向信道,这种信道只能发送或者接收数据。
package main
import "fmt"
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
sendch := make(chan<- int)
go sendData(sendch)
fmt.Println(<-sendch)
}上面程序的第 10 行,我们创建了唯送(Send Only)信道 sendch。chan<- int 定义了唯送信道,因为箭头指向了 chan。在第 12 行,我们试图通过唯送信道接收数据,于是编译器报错:
main.go:11: invalid operation: <-sendch (receive from send-only type chan<- int)一切都很顺利,只不过一个不能读取数据的唯送信道究竟有什么意义呢?
这就需要用到信道转换(Channel Conversion)了。把一个双向信道转换成唯送信道或者唯收(Receive Only)信道都是行得通的,但是反过来就不行。
package main
import "fmt"
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
cha1 := make(chan int)
go sendData(cha1)
fmt.Println(<-cha1)
}在上述程序的第 10 行,我们创建了一个双向信道 cha1。在第 11 行 cha1 作为参数传递给了 sendData 协程。在第 5 行,函数 sendData 里的参数 sendch chan<- int 把 cha1 转换为一个唯送信道。于是该信道在 sendData 协程里是一个唯送信道,而在 Go 主协程里是一个双向信道。该程序最终打印输出 10。
关闭信道和使用 for range 遍历信道
数据发送方可以关闭信道,通知接收方这个信道不再有数据发送过来。
当从信道接收数据时,接收方可以多用一个变量来检查信道是否已经关闭。
v, ok := <- ch上面的语句里,如果成功接收信道所发送的数据,那么 ok 等于 true。而如果 ok 等于 false,说明我们试图读取一个关闭的通道。从关闭的信道读取到的值会是该信道类型的零值。例如,当信道是一个 int 类型的信道时,那么从关闭的信道读取的值将会是 0。
package main
import (
"fmt"
)
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for {
v, ok := <-ch
if ok == false {
break
}
fmt.Println("Received ", v, ok)
}
}在上述的程序中,producer 协程会从 0 到 9 写入信道 chn1,然后关闭该信道。主函数有一个无限的 for 循环(第 16 行),使用变量 ok(第 18 行)检查信道是否已经关闭。如果 ok 等于 false,说明信道已经关闭,于是退出 for 循环。如果 ok 等于 true,会打印出接收到的值和 ok 的值。
Received 0 true
Received 1 true
Received 2 true
Received 3 true
Received 4 true
Received 5 true
Received 6 true
Received 7 true
Received 8 true
Received 9 truefor range 循环用于在一个信道关闭之前,从信道接收数据。
接下来我们使用 for range 循环重写上面的代码。
package main
import (
"fmt"
)
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for v := range ch {
fmt.Println("Received ",v)
}
}在第 16 行,for range 循环从信道 ch 接收数据,直到该信道关闭。一旦关闭了 ch,循环会自动结束。该程序会输出:
Received 0
Received 1
Received 2
Received 3
Received 4
Received 5
Received 6
Received 7
Received 8
Received 9我们可以使用 for range 循环,重写信道的另一个示例这一节里面的代码,提高代码的可重用性。
如果你仔细观察这段代码,会发现获得一个数里的每位数的代码在 calcSquares 和 calcCubes 两个函数内重复了。我们将把这段代码抽离出来,放在一个单独的函数里,然后并发地调用它。
package main
import (
"fmt"
)
func digits(number int, dchnl chan int) {
for number != 0 {
digit := number % 10
dchnl <- digit
number /= 10
}
close(dchnl)
}
func calcSquares(number int, squareop chan int) {
sum := 0
dch := make(chan int)
go digits(number, dch)
for digit := range dch {
sum += digit * digit
}
squareop <- sum
}
func calcCubes(number int, cubeop chan int) {
sum := 0
dch := make(chan int)
go digits(number, dch)
for digit := range dch {
sum += digit * digit * digit
}
cubeop <- sum
}
func main() {
number := 589
sqrch := make(chan int)
cubech := make(chan int)
go calcSquares(number, sqrch)
go calcCubes(number, cubech)
squares, cubes := <-sqrch, <-cubech
fmt.Println("Final output", squares+cubes)
}上述程序里的 digits 函数,包含了获取一个数的每位数的逻辑,并且 calcSquares 和 calcCubes 两个函数并发地调用了 digits。当计算完数字里面的每一位数时,第 13 行就会关闭信道。calcSquares 和 calcCubes 两个协程使用 for range 循环分别监听了它们的信道,直到该信道关闭。程序的其他地方不变,该程序同样会输出:
Final output 1536缓冲信道
什么是缓冲信道?
无缓冲信道的发送和接收过程是阻塞的,我们还可以创建一个有缓冲(Buffer)的信道。只在缓冲已满的情况,才会阻塞向缓冲信道(Buffered Channel)发送数据。同样,只有在缓冲为空的时候,才会阻塞从缓冲信道接收数据。
通过向 make 函数再传递一个表示容量的参数(指定缓冲的大小),可以创建缓冲信道。
ch := make(chan type, capacity)要让一个信道有缓冲,上面语法中的 capacity 应该大于 0。无缓冲信道的容量默认为 0,创建无缓冲信道时,可以省略容量参数。
我们开始编写代码,创建一个缓冲信道。
示例一
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 2)
ch <- "naveen"
ch <- "paul"
fmt.Println(<- ch)
fmt.Println(<- ch)
}在上面程序里的第 9 行,我们创建了一个缓冲信道,其容量为 2。由于该信道的容量为 2,因此可向它写入两个字符串,而且不会发生阻塞。在第 10 行和第 11 行,我们向信道写入两个字符串,该信道并没有发生阻塞。我们又在第 12 行和第 13 行分别读取了这两个字符串。该程序输出:
naveen
paul示例二
我们再看一个缓冲信道的示例,其中有一个并发的 Go 协程来向信道写入数据,而 Go 主协程负责读取数据。该示例帮助我们进一步理解,在向缓冲信道写入数据时,什么时候会发生阻塞。
package main
import (
"fmt"
"time"
)
func write(ch chan int) {
for i := 0; i < 5; i++ {
ch <- i
fmt.Println("successfully wrote", i, "to ch")
}//立即会向 `ch` 写入 0 和 1,接下来发生阻塞,直到 `ch` 内的值被读取
close(ch)
}
func main() {
ch := make(chan int, 2)
go write(ch)
time.Sleep(2 * time.Second)//休眠,等待协程运行
for v := range ch {
fmt.Println("read value", v,"from ch")
time.Sleep(2 * time.Second)
}
}在上面的程序中,第 16 行在 Go 主协程中创建了容量为 2 的缓冲信道 ch,而第 17 行把 ch 传递给了 write 协程。接下来 Go 主协程休眠了两秒。在这期间,write 协程在并发地运行。write 协程有一个 for 循环,依次向信道 ch 写入 0~4。而缓冲信道的容量为 2,因此 write 协程里立即会向 ch 写入 0 和 1,接下来发生阻塞,直到 ch 内的值被读取。因此,该程序立即打印出下面两行:
successfully wrote 0 to ch
successfully wrote 1 to ch打印上面两行之后,write 协程中向 ch 的写入发生了阻塞,直到 ch 有值被读取到。而 Go 主协程休眠了两秒后,才开始读取该信道,因此在休眠期间程序不会打印任何结果。主协程结束休眠后,在第 19 行使用 for range 循环,开始读取信道 ch,打印出了读取到的值后又休眠两秒,这个循环一直到 ch 关闭才结束。所以该程序在两秒后会打印下面两行:
read value 0 from ch
successfully wrote 2 to ch该过程会一直进行,直到信道读取完所有的值,并在 write 协程中关闭信道。最终输出如下:
successfully wrote 0 to ch
successfully wrote 1 to ch
read value 0 from ch
successfully wrote 2 to ch
read value 1 from ch
successfully wrote 3 to ch
read value 2 from ch
successfully wrote 4 to ch
read value 3 from ch
read value 4 from ch死锁
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 2)
ch <- "naveen"
ch <- "paul"
ch <- "steve"
fmt.Println(<-ch)
fmt.Println(<-ch)
}在上面程序里,我们向容量为 2 的缓冲信道写入 3 个字符串。当在程序控制到达第 3 次写入时(第 11 行),由于它超出了信道的容量,因此这次写入发生了阻塞。现在想要这次写操作能够进行下去,必须要有其它协程来读取这个信道的数据。但在本例中,并没有并发协程来读取这个信道,因此这里会发生死锁(deadlock)。程序会在运行时触发 panic,信息如下:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
/tmp/sandbox274756028/main.go:11 +0x100长度 vs 容量
缓冲信道的容量是指信道可以存储的值的数量。我们在使用 make 函数创建缓冲信道的时候会指定容量大小。
缓冲信道的长度是指信道中当前排队的元素个数。
代码可以把一切解释得很清楚。:)
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 3)
ch <- "naveen"
ch <- "paul"
fmt.Println("capacity is", cap(ch))
fmt.Println("length is", len(ch))
fmt.Println("read value", <-ch)
fmt.Println("new length is", len(ch))
}在上面的程序里,我们创建了一个容量为 3 的信道,于是它可以保存 3 个字符串。接下来,我们分别在第 9 行和第 10 行向信道写入了两个字符串。于是信道有两个字符串排队,因此其长度为 2。在第 13 行,我们又从信道读取了一个字符串。现在该信道内只有一个字符串,因此其长度变为 1。该程序会输出:
capacity is 3
length is 2
read value naveen
new length is 1WaitGroup
在本教程的下一节里,我们会讲到工作池(Worker Pools)。而 WaitGroup 用于实现工作池,因此要理解工作池,我们首先需要学习 WaitGroup。
WaitGroup 用于等待一批 Go 协程执行结束。程序控制会一直阻塞,直到这些协程全部执行完毕。假设我们有 3 个并发执行的 Go 协程(由 Go 主协程生成)。Go 主协程需要等待这 3 个协程执行结束后,才会终止。这就可以用 WaitGroup 来实现。
理论说完了,我们编写点儿代码吧。:)
package main
import (
"fmt"
"sync"
"time"
)
func process(i int, wg *sync.WaitGroup) { //注意一定是传递的地址,使用同一个waitgroup变量
fmt.Println("started Goroutine ", i)
time.Sleep(2 * time.Second)
fmt.Printf("Goroutine %d ended\n", i)
wg.Done()
}
func main() {
no := 3
var wg sync.WaitGroup
for i := 0; i < no; i++ {
wg.Add(1)
go process(i, &wg)
}
wg.Wait()
fmt.Println("All go routines finished executing")
}WaitGroup 是一个结构体类型,我们在第 18 行创建了 WaitGroup 类型的变量,其初始值为零值。WaitGroup 使用计数器来工作。当我们调用 WaitGroup 的 Add 并传递一个 int 时,**WaitGroup 的计数器会加上 Add 的传参**。要减少计数器,可以调用 WaitGroup 的 Done() 方法。Wait() 方法会阻塞调用它的 Go 协程,直到计数器变为 0 后才会停止阻塞。
上述程序里,for 循环迭代了 3 次,我们在循环内调用了 wg.Add(1)(第 20 行)。因此计数器变为 3。for 循环同样创建了 3 个 process 协程,然后在第 23 行调用了 wg.Wait(),确保 Go 主协程等待计数器变为 0。在第 13 行,process 协程内调用了 wg.Done,可以让计数器递减。一旦 3 个子协程都执行完毕(即 wg.Done() 调用了 3 次),那么计数器就变为 0,于是主协程会解除阻塞。
在第 21 行里,传递 wg 的地址是很重要的。如果没有传递 wg 的地址,那么每个 Go 协程将会得到一个 WaitGroup 值的拷贝,因而当它们执行结束时,main 函数并不会知道。
该程序输出:
started Goroutine 2
started Goroutine 0
started Goroutine 1
Goroutine 0 ended
Goroutine 2 ended
Goroutine 1 ended
All go routines finished executing由于 Go 协程的执行顺序不一定,因此你的输出可能和我不一样。:)
工作池的实现
缓冲信道的重要应用之一就是实现工作池。
一般而言,工作池就是一组等待任务分配的线程。一旦完成了所分配的任务,这些线程可继续等待任务的分配。
我们会使用缓冲信道来实现工作池。我们工作池的任务是计算所输入数字的每一位的和。例如,如果输入 234,结果会是 9(即 2 + 3 + 4)。向工作池输入的是一列伪随机数。
我们工作池的核心功能如下:
- 创建一个 Go 协程池,监听一个等待作业分配的输入型缓冲信道。
- 将作业添加到该输入型缓冲信道中。
- 作业完成后,再将结果写入一个输出型缓冲信道。
- 从输出型缓冲信道读取并打印结果。
我们会逐步编写这个程序,让代码易于理解。
第一步就是创建一个结构体,表示作业和结果。
type Job struct {
id int
randomno int
}
type Result struct {
job Job
sumofdigits int
}所有 Job 结构体变量都会有 id 和 randomno 两个字段,randomno 用于计算其每位数之和。
而 Result 结构体有一个 job 字段,表示所对应的作业,还有一个 sumofdigits 字段,表示计算的结果(每位数字之和)。
第二步是分别创建用于接收作业和写入结果的缓冲信道。
var jobs = make(chan Job, 10)
var results = make(chan Result, 10)工作协程(Worker Goroutine)会监听缓冲信道 jobs 里更新的作业。一旦工作协程完成了作业,其结果会写入缓冲信道 results。
如下所示,digits 函数的任务实际上就是计算整数的每一位之和,最后返回该结果。为了模拟出 digits 在计算过程中花费了一段时间,我们在函数内添加了两秒的休眠时间。
func digits(number int) int {
sum := 0
no := number
for no != 0 {
digit := no % 10
sum += digit
no /= 10
}
time.Sleep(2 * time.Second)
return sum
}然后,我们写一个创建工作协程的函数。
func worker(wg *sync.WaitGroup) {
for job := range jobs {
output := Result{job, digits(job.randomno)}
results <- output
}
wg.Done()
}上面的函数创建了一个工作者(Worker),读取 jobs 信道的数据,根据当前的 job 和 digits 函数的返回值,创建了一个 Result 结构体变量,然后将结果写入 results 缓冲信道。worker 函数接收了一个 WaitGroup 类型的 wg 作为参数,当所有的 jobs 完成的时候,调用了 Done() 方法。
createWorkerPool 函数创建了一个 Go 协程的工作池。
func createWorkerPool(noOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < noOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}上面函数的参数是需要创建的工作协程的数量。在创建 Go 协程之前,它调用了 wg.Add(1) 方法,于是 WaitGroup 计数器递增。接下来,我们创建工作协程,并向 worker 函数传递 wg 的地址。创建了需要的工作协程后,函数调用 wg.Wait(),等待所有的 Go 协程执行完毕。所有协程完成执行之后,函数会关闭 results 信道。因为所有协程都已经执行完毕,于是不再需要向 results 信道写入数据了。
现在我们已经有了工作池,我们继续编写一个函数,把作业分配给工作者。
func allocate(noOfJobs int) {
for i := 0; i < noOfJobs; i++ {
randomno := rand.Intn(999)
job := Job{i, randomno}
jobs <- job
}
close(jobs)
}上面的 allocate 函数接收所需创建的作业数量作为输入参数,生成了最大值为 998 的伪随机数,并使用该随机数创建了 Job 结构体变量。这个函数把 for 循环的计数器 i 作为 id,最后把创建的结构体变量写入 jobs 信道。当写入所有的 job 时,它关闭了 jobs 信道。
下一步是创建一个读取 results 信道和打印输出的函数。
func result(done chan bool) {
for result := range results {
fmt.Printf("Job id %d, input random no %d , sum of digits %d\n", result.job.id, result.job.randomno, result.sumofdigits)
}
done <- true
}result 函数读取 results 信道,并打印出 job 的 id、输入的随机数、该随机数的每位数之和。result 函数也接受 done 信道作为参数,当打印所有结果时,done 会被写入 true。
现在一切准备充分了。我们继续完成最后一步,在 main() 函数中调用上面所有的函数。
func main() {
startTime := time.Now()
noOfJobs := 100
go allocate(noOfJobs)
done := make(chan bool)
go result(done)
noOfWorkers := 10
createWorkerPool(noOfWorkers)
<-done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}我们首先在 main 函数的第 2 行,保存了程序的起始时间,并在最后一行(第 12 行)计算了 endTime 和 startTime 的差值,显示出程序运行的总时间。由于我们想要通过改变协程数量,来做一点基准指标(Benchmark),所以需要这么做。
我们把 noOfJobs 设置为 100,接下来调用了 allocate,向 jobs 信道添加作业。
我们创建了 done 信道,并将其传递给 result 协程。于是该协程会开始打印结果,并在完成打印时发出通知。
通过调用 createWorkerPool 函数,我们最终创建了一个有 10 个协程的工作池。main 函数会监听 done 信道的通知,等待所有结果打印结束。
为了便于参考,下面是整个程序。我还引用了必要的包。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
type Job struct {
id int
randomno int
}
type Result struct {
job Job
sumofdigits int
}
var jobs = make(chan Job, 10)
var results = make(chan Result, 10)
func digits(number int) int {
sum := 0
no := number
for no != 0 {
digit := no % 10
sum += digit
no /= 10
}
time.Sleep(2 * time.Second)
return sum
}
func worker(wg *sync.WaitGroup) {
for job := range jobs {
output := Result{job, digits(job.randomno)}
results <- output
}
wg.Done()
}
func createWorkerPool(noOfWorkers int) {
var wg sync.WaitGroup
for i := 0; i < noOfWorkers; i++ {
wg.Add(1)
go worker(&wg)
}
wg.Wait()
close(results)
}
func allocate(noOfJobs int) {
for i := 0; i < noOfJobs; i++ {
randomno := rand.Intn(999)
job := Job{i, randomno}
jobs <- job
}
close(jobs)
}
func result(done chan bool) {
for result := range results {
fmt.Printf("Job id %d, input random no %d , sum of digits %d\n", result.job.id, result.job.randomno, result.sumofdigits)
}
done <- true
}
func main() {
startTime := time.Now()
noOfJobs := 100
go allocate(noOfJobs)
done := make(chan bool)
go result(done)
noOfWorkers := 10
createWorkerPool(noOfWorkers)
<-done
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}为了更精确地计算总时间,请在你的本地机器上运行该程序。
该程序输出:
Job id 1, input random no 636, sum of digits 15
Job id 0, input random no 878, sum of digits 23
Job id 9, input random no 150, sum of digits 6
...
total time taken 20.01081009 seconds程序总共会打印 100 行,对应着 100 项作业,然后最后会打印一行程序消耗的总时间。你的输出会和我的不同,因为 Go 协程的运行顺序不一定,同样总时间也会因为硬件而不同。在我的例子中,运行程序大约花费了 20 秒。
现在我们把 main 函数里的 noOfWorkers 增加到 20。我们把工作者的数量加倍了。由于工作协程增加了(准确说来是两倍),因此程序花费的总时间会减少(准确说来是一半)。在我的例子里,程序会打印出 10.004364685 秒。
...
total time taken 10.004364685 seconds现在我们可以理解了,随着工作协程数量增加,完成作业的总时间会减少。你们可以练习一下:在 main 函数里修改 noOfJobs 和 noOfWorkers 的值,并试着去分析一下结果。
questions
func allocate(noOfJobs int) {
for i := 0; i < noOfJobs; i++ { randomno := rand.Intn(999) job := Job{i, randomno} jobs <- job } close(jobs) } 如果for循环结束后,jobs里面的数据worker还来不及取走,这时执行到close,会不会导致works取数据失败?或者取不到足额的任务?
这里 close 和关闭文件的概念不同。
golang 里的 close 只是用于通知信道的接收方,所有数据都已经发送完毕,信道没有真正关闭。
若用 for range 接收数据时,对于关闭了的信道,会接收完剩下的有效数据,并退出循环。如果没有 close 提示数据发送完毕的话,for range 会接收完剩下所有有效数据后发生阻塞。
所以接收方 worker 是可以把 jobs 剩下的数据取走的。后面垃圾收集器会自动回收掉该信道的内存。
爬虫(Web crawler)
从一个种子网页 URL 开始
通过 HTTP 请求,获取其内容文本
解析其内容包含的所有 URL,针对所有 URL 重复过程 2,3
为了避免重复抓取,需要记下所有抓取过的 URL。
由于:
- 网页数量巨大
- 网络请求较慢
一个接一个的抓取用时太长,因此需要并行抓取。这里面有个难点,就是如何判断已经抓取完所有网页,并需要结束抓取。
抓取代码
代码在阅读材料中有。
package main
import (
"fmt"
"sync"
)
//
// Several solutions to the crawler exercise from the Go tutorial
// https://tour.golang.org/concurrency/10
//
//
// Serial crawler
//
func Serial(url string, fetcher Fetcher, fetched map[string]bool) {
if fetched[url] {
return
}
fetched[url] = true
urls, err := fetcher.Fetch(url)
if err != nil {
return
}
for _, u := range urls {
Serial(u, fetcher, fetched)
}
return
}
//
// Concurrent crawler with shared state and Mutex
//
type fetchState struct {
mu sync.Mutex//除了bool数组之外还多了一个互斥锁mu。它的原理就是用来给共享变量fetched加锁,保证在多线程爬虫时,每次只有一个线程能访问fetched变量。
fetched map[string]bool
}
func ConcurrentMutex(url string, fetcher Fetcher, f *fetchState) {//之所以使用*就是为了所有的线程都使用shared memory
f.mu.Lock()
already := f.fetched[url]//这里两个线程可能对于同一个网页提取(不同的url中的引用,然后都得到了false
f.fetched[url] = true//所以放在一起执行,line43,44是原子操作
f.mu.Unlock()//当mu已经被锁上时,任何试图访问它的线程都会阻塞在mu.Lock()处,直到mu被释放掉才能往下进行(可以理解为二元信号量的wait操作)
if already {
return
}
urls, err := fetcher.Fetch(url)
if err != nil {
return
}
var done sync.WaitGroup//用来确定何时结束爬虫的,WaitGroup 对象内部有一个计数器,最初从0开始,它有三个方法:Add(), Done(), Wait() 用来控制计数器的数量。Add(n) 把计数器设置为n ,Done() 每次把计数器-1 ,wait() 会阻塞代码的运行,直到计数器地值减为0 (可以理解为counting semaphore)
for _, u := range urls {
done.Add(1)
u2 := u//因为在一次循环之中用了u之后,传入的如果是地址,第二次循环的u会变化,但是其实我们并不期望这样的变化
go func() {//调用函数或者方法时,在前面加上关键字 go,可以让一个新的 Go 协程并发地运行。对于每个域名下面的链接,会再启动一个ConcurrentMutex线程来抓取,而不是单纯的递归,这样就实现了多线程,类似于c中的fork()函数
defer done.Done()//避免有的函数调用失败,无论如何都要调用done
ConcurrentMutex(u2, fetcher, f)
}()
//go func(u string) {//go中默认传输的不是地址,是一份u的copy,注释掉的代码实现了一样的效果
// defer done.Done()
// ConcurrentMutex(u, fetcher, f)
//}(u)
}
done.Wait()
return
}
func makeState() *fetchState {
f := &fetchState{}
f.fetched = make(map[string]bool)
return f
}
//
// Concurrent crawler with channels
//
func worker(url string, ch chan []string, fetcher Fetcher) {
urls, err := fetcher.Fetch(url)
if err != nil {
ch <- []string{}
} else {
ch <- urls
}
}
func master(ch chan []string, fetcher Fetcher) {
n := 1
fetched := make(map[string]bool)
for urls := range ch {
for _, u := range urls {
if fetched[u] == false {
fetched[u] = true
n += 1
go worker(u, ch, fetcher)
}
}
n -= 1
if n == 0 {
break
}
}
}
func ConcurrentChannel(url string, fetcher Fetcher) {
ch := make(chan []string)
go func() {
ch <- []string{url}
}()
master(ch, fetcher)
}
//
// main
//
func main() {
fmt.Printf("=== Serial===\n")
Serial("http://golang.org/", fetcher, make(map[string]bool))
fmt.Printf("=== ConcurrentMutex ===\n")
ConcurrentMutex("http://golang.org/", fetcher, makeState())
fmt.Printf("=== ConcurrentChannel ===\n")
ConcurrentChannel("http://golang.org/", fetcher)
}
//
// Fetcher
//
type Fetcher interface {
// Fetch returns a slice of URLs found on the page.
Fetch(url string) (urls []string, err error)
}
// fakeFetcher is Fetcher that returns canned results.
type fakeFetcher map[string]*fakeResult
type fakeResult struct {
body string
urls []string
}
func (f fakeFetcher) Fetch(url string) ([]string, error) {
if res, ok := f[url]; ok {
fmt.Printf("found: %s\n", url)
return res.urls, nil
}
fmt.Printf("missing: %s\n", url)
return nil, fmt.Errorf("not found: %s", url)
}
// fetcher is a populated fakeFetcher.
var fetcher = fakeFetcher{
"http://golang.org/": &fakeResult{
"The Go Programming Language",
[]string{
"http://golang.org/pkg/",
"http://golang.org/cmd/",
},
},
"http://golang.org/pkg/": &fakeResult{
"Packages",
[]string{
"http://golang.org/",
"http://golang.org/cmd/",
"http://golang.org/pkg/fmt/",
"http://golang.org/pkg/os/",
},
},
"http://golang.org/pkg/fmt/": &fakeResult{
"Package fmt",
[]string{
"http://golang.org/",
"http://golang.org/pkg/",
},
},
"http://golang.org/pkg/os/": &fakeResult{
"Package os",
[]string{
"http://golang.org/",
"http://golang.org/pkg/",
},
},
}为了简便起见,这其实只是一个假的爬虫……并没有涉及网络访问,它的作用就是在fetcher中建立一个string->fakeResult类型的hash table,表示每个网页上的链接列表,并通过爬虫函数读取它们。为了演示go语言的并发,代码中实现了三种函数:Serial,ConcurrentMutex,ConcurrentChannel
串行爬取。深度优先遍历(DFS )全部网页构成的图结构,利用一个名为 fetched 的 set 来保存所有已经抓取过的 URL。
func Serial(url string, fetcher Fetcher, fetched map[string]bool) {
if fetched[url] {
return
}
fetched[url] = true
urls, err := fetcher.Fetch(url)
if err != nil {
return
}
for _, u := range urls {
Serial(u, fetcher, fetched)
}
return
}
//。。。
Serial("http://golang.org/", fetcher, make(map[string]bool))
//。。。它的输入参数包括根域名url,fetcher(前面提到过的hash table),和一个bool数组fetched(用来记录哪些网站被访问过了)。注意163行这里有个神奇的用法make(),参考Go内建函数make及切片slice、映射map详解。serial函数本身比较简单,基本思路就是对fetcher中的每个域名,递归抓取它下面的链接(在fakeResult里面)。
并行爬取
type fetchState struct {
mu sync.Mutex
fetched map[string]bool
}
func ConcurrentMutex(url string, fetcher Fetcher, f *fetchState) {//之所以使用*就是为了所有的线程都使用shared memory
f.mu.Lock()
already := f.fetched[url]//这里两个线程可能对于同一个网页提取(不同的url中的引用,然后都得到了false
f.fetched[url] = true//所以放在一起执行,希望line43,44是原子操作
f.mu.Unlock()
if already {
return
}
urls, err := fetcher.Fetch(url)
if err != nil {
return
}
var done sync.WaitGroup
for _, u := range urls {
done.Add(1)
u2 := u//因为在一次循环之中用了u之后,传入的如果是地址,第二次循环的u会变化,但是其实我们并不期望这样的变化
go func() {
defer done.Done()//避免有的函数调用失败,无论如何都要调用done
ConcurrentMutex(u2, fetcher, f)
}()
//go func(u string) {//go中默认传输的不是地址,是一份u的copy,注释掉的代码实现了一样的效果
// defer done.Done()
// ConcurrentMutex(u, fetcher, f)
//}(u)
}
done.Wait()
return
}- 将抓取部分使用 go 关键字变为并行。但如果仅这么改造,不利用某些手段(sync.WaitGroup)等待子 goroutine,而直接返回,那么可能只会抓取到种子 URL,同时造成子 goroutine 的泄露。
- 如果访问已经抓取的 URL 集合 fetched 不加锁,很可能造成多次拉取同一个网页。
WaitGroup
var done sync.WaitGroup
for _, u := range urls {
done.Add(1)
go func(u string) {
defer done.Done()
ConcurrentMutex(u, fetcher, f)
}(u) // u 被拷贝
}
done.Wait()WaitGroup 内部维护了一个计数器:调用 wg.Add(n) 时候会增加 n;调用 wait.Done() 时候会减少 1。这时候调用 wg.Wait() 会一直阻塞直到当计数器变为 0 。所以 WaitGroup 很适合等待一组 goroutine 都结束的场景。
Q&A
如果 goroutine 异常退出没有调用 wg.Done () 怎么办?可以使用 defer 将其写在 goroutine 开始:
defer wg.Done()两个 goroutine 同时调用 wg.Done () 会有竞争(race),以至于内部计数器不能正确减少两次吗?WaitGroup 应该有相应机制(锁什么的)来保证 Done () 的原子性。
定义匿名函数时,匿名函数中变量和外层函数同名变量间的关系?这是个闭包(closure)问题。如果匿名函数中变量没有被参数覆盖(如上述代码中
fetcher),就会和外层同名变量引用同一个地址。如果通过传参传递(如上述代码中u),哪怕参数和外层变量看起来一样,但匿名函数使用的也是传进来的参数,而非外层变量;尤其针对 for 循环变量,我们通常通过参数来将其在调用时拷贝一次,否则 for 循环启动的所有 goroutine 都会指向这个不断被 for 循环赋值改变的变量。对于闭包,go 中有个” 变量逃逸 “(Variable Escape)的说法,如果某个变量在函数声明周期结束时仍被引用,则将其分被到堆而非函数栈上。对闭包来说,某个变量同时被内层和外层函数引用,则其会被分配到堆上。
既然字符串
u是不可变(immutable)的,为什么所有 goroutine 还会引用到不断变化的值?string 的确是不可变的,但是u的值一直在变,而 goroutine 和外层 goroutine 共享 u 的引用。
去掉锁
如果在更新 map 的时候去掉锁,运行几次发现并没有什么异常,因为 race 其实很难检测。好在 go 提供了竞态分析工具帮你来找到潜在含有竞态的地方:go run -race crawler.go
注意该工具没有做静态分析,而是在动态执行过程中观察、记录各个 goroutine 的执行轨迹,进行分析。
线程数量
Q&A
\1. 该代码在整个运行中会同时多少线程在运行(goroutine)?
该代码并没有做明显的限制,但是其明显和 URL 数量、抓取时间正相关。例子中输入只有五个 URL,因此没有什么问题。但在现实中,这么做可能会同时启动上百万个 goroutine。因此一个改进是,实现启动一个固定数量的 worker 池子,每个 worker 干完后就去要 / 被分配下一个任务。
使用 channel 通信
我们可以实现一个新的爬虫版本,不用锁 + 共享变量,而用 go 中内置的语法:channel 来通信。具体做法类似实现一个生产者消费者模型,使用 channel 做消息队列。
- 初始将种子 url 塞进 channel。
- 消费者:master 不断从 channel 中取出 urls,判断是否抓取过,然后启动新的 worker goroutine 去抓取。
- 生产者:worker goroutine 抓取到给定的任务 url,并将解析出的结果 urls 塞回 channel。
- master 使用一个变量 n 来追踪发出的任务数;往发出一份任务增加一;从 channel 中获取并处理完一份结果(即将其再安排给 worker)减掉一;当所有任务都处理完时,退出程序。
func worker(url string, ch chan []string, fetcher Fetcher) {
urls, err := fetcher.Fetch(url)
if err != nil {
ch <- []string{}
} else {
ch <- urls
}
}
func master(ch chan []string, fetcher Fetcher) {
n := 1
fetched := make(map[string]bool)
for urls := range ch {
for _, u := range urls {
if fetched[u] == false {
fetched[u] = true
n += 1
go worker(u, ch, fetcher)
}
}
n -= 1
if n == 0 {
break
}
}
}
func ConcurrentChannel(url string, fetcher Fetcher) {
ch := make(chan []string)
go func() {
ch <- []string{url}
}()
master(ch, fetcher)
}Q&A:
- master 读 channel,多 worker 写 channel,不会有竞争问题吗?channel 是线程安全的。
- channel 不需要最后 close 吗?我们用 n 追踪了所有执行中的任务数,因此当 n 为 0 退出时,channel 中不存在任何任务 / 结果,因此 master/worker 都不会对 channel 存在引用,稍后 gc collector 会将其回收。
- 为什么在 ConcurrentChannel 需要用 goroutine 往 channel 中写一个 url?否则 master 在读取的时候会一直阻塞。并且 channel 是一个非缓冲 channel,如果不用 goroutine,将会永远阻塞在写的时候。
参考:
https://www.qtmuniao.com/2020/02/29/6-824-video-notes-2/
https://golangbot.com/buffered-channels-worker-pools/
作者:Nick Coghlan 译者:Noluye 校对:polaris1119